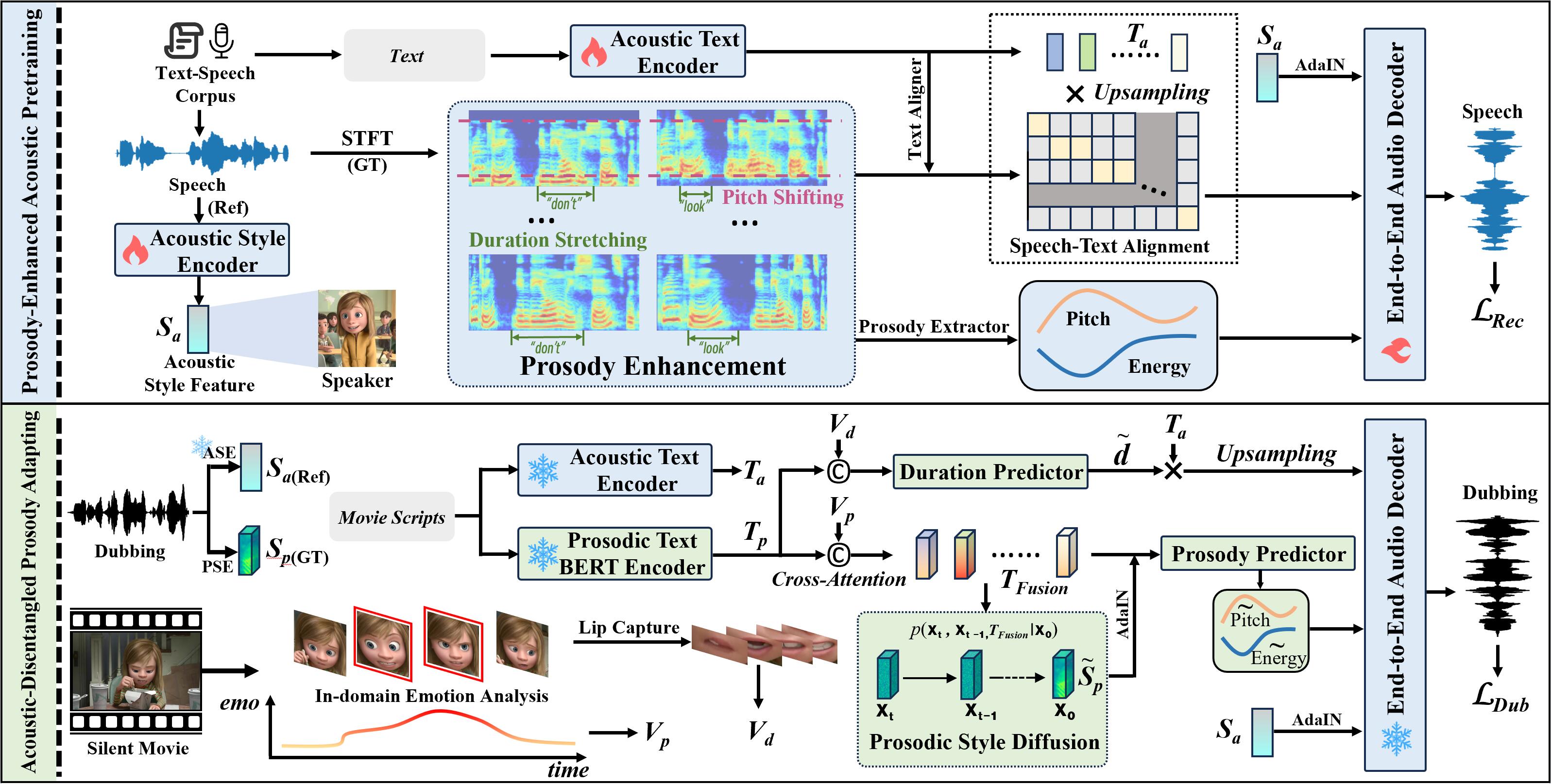
Movie dubbing describes the process of transforming a script into speech that aligns temporally and emotionally with a given movie clip while exemplifying the speaker’s voice demonstrated in a short reference audio clip. This task demands the model bridge character performances and complicated prosody structures to build a high-quality video-synchronized dubbing track. The limited scale of movie dubbing datasets, along with the background noise inherent in audio data, hinder the acoustic modeling performance of trained models. To address these issues, we propose an acoustic-prosody disentangled two-stage method to achieve high-quality dubbing generation with precise prosody alignment. First, we propose a prosody-enhanced acoustic pre-training to develop robust acoustic modeling capabilities. Then, we freeze the pre-trained acoustic system and design a disentangled framework to model prosodic text features and dubbing style while maintaining acoustic quality. Additionally, we incorporate an in-domain emotion analysis module to reduce the impact of visual domain shifts across different movies, thereby enhancing emotion-prosody alignment. Extensive experiments show that our method performs favorably against the state-of-the-art models on two primary benchmarks. The official demos are available here.
V2C-Animation sample on Dub 1.0
Sample #1
Script: You see, babies aren’t getting as much love as we used to.
V2C-Net
HPMDubbing
StyleDubber
Speaker2Dubber
Ours
GT
Sample #2
Script: Wow, they’re shiny. I’m sam.
V2C-Net
HPMDubbing
StyleDubber
Speaker2Dubber
Ours
GT
Sample #3
Script: And everyone had to go on this long, sucky walk.
V2C-Net
HPMDubbing
StyleDubber
Speaker2Dubber
Ours
GT
Sample #4
Script: Sly fox, dumb bunny.
V2C-Net
HPMDubbing
StyleDubber
Speaker2Dubber
Ours
GT
Sample #5
Script: Do you have to go now? I mean, you know, it’s getting late.
V2C-Net
HPMDubbing
StyleDubber
Speaker2Dubber
Ours
GT
V2C-Animation sample on Dub 2.0
Sample #1
Script: Your father’s out there “entertaining” them.
Reference Audio:
V2C-Net
HPMDubbing
StyleDubber
Speaker2Dubber
Ours
GT
Sample #2
Script: My chest hairs are tingling. Something’s wrong.
Reference Audio:
V2C-Net
HPMDubbing
StyleDubber
Speaker2Dubber
Ours
GT
Sample #3
Script: Why did you bring me here?
V2C-Net
HPMDubbing
StyleDubber
Speaker2Dubber
Ours
GT
Zero-shot sample test
Sample #1
Script: It’s not where it’s been. It’s where it will take you.
Ground truth:
Reference Audio From GRID benchmark #1
Reference Audio From GRID benchmark #2
Reference Audio From GRID benchmark #3
Sample #2
Script: And each one is special.
Ground truth:
Reference Audio From GRID benchmark #1
Reference Audio From GRID benchmark #2
Reference Audio From GRID benchmark #3
Sample #3
Script: We will get out of here
Ground truth:
Reference Audio From GRID benchmark #1
Reference Audio From GRID benchmark #2
Reference Audio From GRID benchmark #3
Sample #4
Script: She’s the reason you wanted to cross the bridge.